

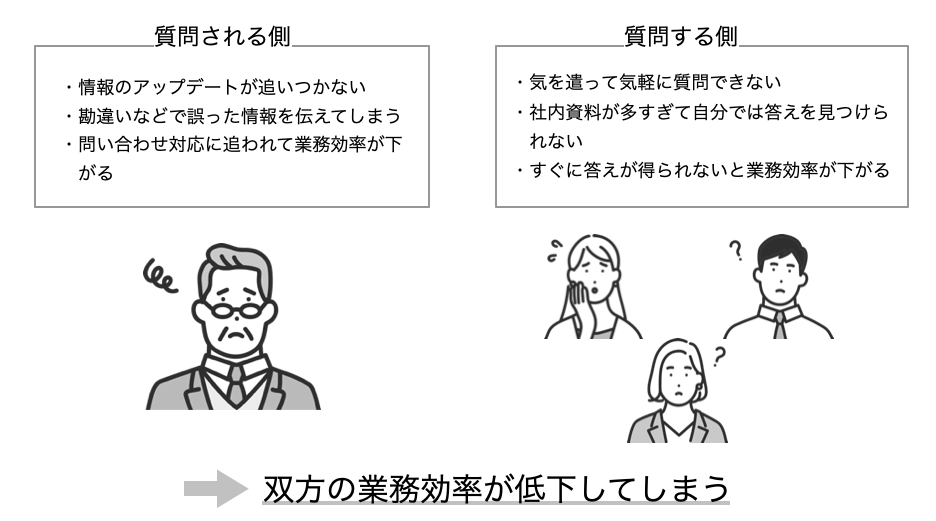
社内では、情報の共有がなされてるが、以下の問題がある。
- 分散した情報の統合
GPTsを社内のドキュメントやFAQと連携させることで、部署ごと・個人ごとにバラバラに存在していた情報を一括で検索・参照しやすくできます。- 例:共有フォルダやナレッジベースにあるマニュアル、FAQ、の内容をGPTに学習させ、問い合わせを尋ねるだけで適切な回答を返す。
- 質問ハードルの低減
チャット形式のインターフェースであれば、上司や同僚に直接質問しづらい・何をどう聞いていいか分からない状況でも、気軽に尋ねやすい環境を作れる。- 気兼ねなくいつでも聞けるため、属人的な質問対応の負荷が軽減される。
- 回答の精度向上(+定期メンテナンスの必要性)
GPTsは大量のテキストを元に推論しますが、元情報が古いままでは当然誤った回答につながる可能性があります。そこで、運用時には「最新情報への更新」と「モデルへのフィードバックループ(誤情報や古い情報の修正)」を社内でルール化する必要があります。- 定期的に学習データを更新する仕組み
- 誤回答があった場合の修正フローや、アップデートの履歴管理
- 問い合わせ対応の分散と効率化
GPTが一次回答を担当し、より高度で専門的な質問や判断が必要なケースだけを担当者へエスカレーションする形にすれば、負担が大幅に軽減されます。- 既存のFAQやマニュアルに書いてあることは自動で回答
- 新しい質問や現行ルールにない問い合わせは担当者が対応し、その結果を再度ナレッジとして蓄積
実装時のポイント
- 社内ナレッジ(会社内で共有される知識や情報)の整理
GPTを導入する前に、まずは社内に散在しているドキュメントやマニュアルの整理が必要になります。正確で最新の情報がそろっていればこそ、AIによる回答の信頼性が高まります。 - 情報の機密性やアクセス権
社内文書には機密情報が含まれることも多いため、情報の取り扱いルールを明確に定め、GPTとの連携にあたってもアクセス制限やログ管理を行う必要があります。 - 継続的なフィードバックと更新
導入後は、利用者からの「回答の正確性」や「アップデートの要望」などのフィードバックを集め、モデルやデータを都度見直すプロセスを回すことが重要です。
まとめ
図にもあるように、社内でのナレッジ共有が属人化していると、質問される側・質問する側の双方で業務効率が落ちてしまいます。これに対してGPTを導入する。
- 大量の社内文書の中から瞬時に回答を見つけられる
- 担当者の負担が減り、コア業務に専念できる
- 社内で“AIに聞く”文化が根付いて質問のハードルが下がる
といった効果が期待できます。ただし、導入時には情報の正確性を保つ運用設計や機密データの管理が非常に大切です。そうした前提をきちんと整えたうえでGPTを活用すれば、社内の知識共有を加速させ、属人化による非効率を解消する大きな助けになるでしょう。(ChatGPT:GPTsの作り方(初級))


