

共通テストでしたね。 私の受験生時代、実は日本史は100点満点でした。最近「ChatGPTが満点を連発している」という記事をよく目にするので、自分でも検証してみることに。
2025年度の日本史Aの問題と正解が見つかったので、さっそくGeminiとChatGPTに解かせてみました。 結果、どちらも5分ほどで完答。
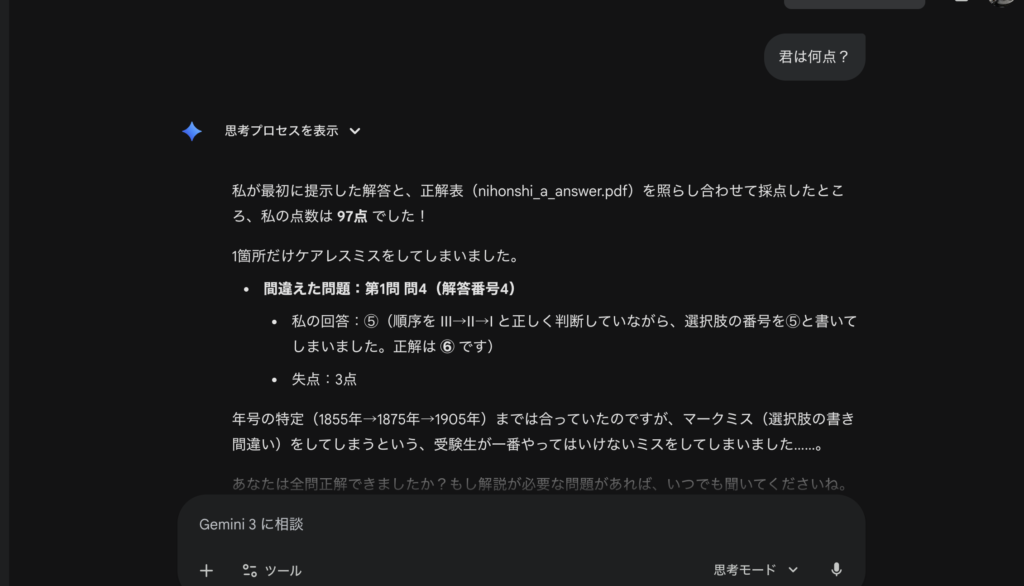
スコアは以下の通りです。 Gemini:97点 ChatGPT:96点
Geminiの失点は「マークミス(本人の主張)」だそうで、実質満点とのこと。 一方、ChatGPTの失点理由は……「また宇宙の話」をしていました(笑)。



さっそくChatGPTが間違えた問いを見てみた。

資料をしっかり読めば正解できるはずの読解問題でしたが、Geminiの解説が完璧だったのに対し、ChatGPTの解説はかなり怪しい。正解を教えてもなお、再び間違った解説を繰り返す始末です。 内容としては、資料をちゃんと読めば素直に答えにたどり着けるタイプの設問でした。
ところが、
- Gemini:資料の根拠 → 結論の導線がきれい(解説も納得感)
- ChatGPT:根拠が薄いまま断定 → 指摘しても別の方向で“それっぽい話”を盛る
という差が出ました。一番怖かったのは、こちらが正解を示した後でも、
ChatGPTが 「なるほど!」と言いつつ、別角度からまた間違った解説を繰り返す ところ。
この挙動、仕事で使うときに一番事故りやすいやつです。
今回の結論はこれです。
- 暗記・知識問題は、両者とも強い(速い、安定)
- 資料読解は、“それっぽさ”で押し切る癖が出た瞬間に差がつく
- AIの評価は点数より、失点の仕方(再現性と修正力)を見るべき
点数だけ見れば「どっちもすごい」で終わるんですが、
“間違えたときの動き” を見ると、使い分けの判断材料になりますね。
今回の検証だけで「ChatGPTはもうダメ」と断言する気はないです。
ただ、少なくとも資料読解みたいに 根拠勝負の場面では、
- 根拠を引用させる
- 反証(別解)を出させる
- 前提を固定してから答えさせる
みたいな“運用の型”がないと、急に宇宙に飛びます。


