

例えば、画像生成AIは、プロンプトに含まれる単語や文脈から「それらしい平均像」を引き出して画像を作ります。このとき、学習データや美的テンプレートの偏りがあると、出力にも同じ方向の偏りが現れやすくなります。


まず大きいのが、学習データの比率と露出の問題です。インターネット上の人物画像は、広告、ファッション、映画、ストックフォトなどの影響で、欧米圏の顔立ちが多く流通しています。その結果、モデル内部で「人間」や「魅力的な人物」の基準が、相対的に欧米寄りになりやすいのです。
次に、“美”を表す言葉と見た目の結びつきがあります。「beautiful」「handsome」「model」「cinematic」といった語は、学習上、ハリウッド的な照明や欧米系ストックフォトの作法と強く関連づけられていることが少なくありません。そのため、美しさを強調するほど、彫りの深さや明るい肌トーンなどが前に出てくる場合があります。これは「美の既定値」が働いている状態だと考えると理解しやすいでしょう。
さらに、スタイル指定が顔立ちまで巻き込む点も重要です。「シネマティック」「雑誌風」「ハイファッション」といった指定は、撮影文化そのものを呼び出します。そこにはライティングや色調だけでなく、被写体の選ばれ方や造形の傾向も含まれるため、顔の特徴までテンプレート側に引っ張られやすくなります。
加えて、情報が不足するとAIは“安全な平均”に逃げる傾向があります。プロンプトが曖昧な場合、もっとも破綻しにくい既定値が選ばれますが、その既定値がデータ量の多い欧米寄りである、というわけです。
では「海外で開発されたから」なのでしょうか。実際には、開発国そのものよりも、学習データの構成、タグの付き方、美的テンプレート、そしてプロンプトの具体性が結果を左右します。英語圏ユーザー中心の設計であれば、その方向に最適化されやすい面はありますが、主因はあくまで「データと既定値」です。
“欧米っぽさ”を抑える実務的な工夫
有効なのは、属性を明示することです。「日本人」「Japanese / East Asian」などを入れると、平均が日本側に寄りやすくなります。
次に、“美”ワードの使い方を慎重にすること。「beautiful model」ではなく、「自然光のスナップ」「実在感のある一般的な日本人ポートレート」など、具体的で控えめな表現が安定します。
可能であれば、参照画像を使うのが最も確実です。顔の特徴が固定され、スタイル指定だけを乗せやすくなります。
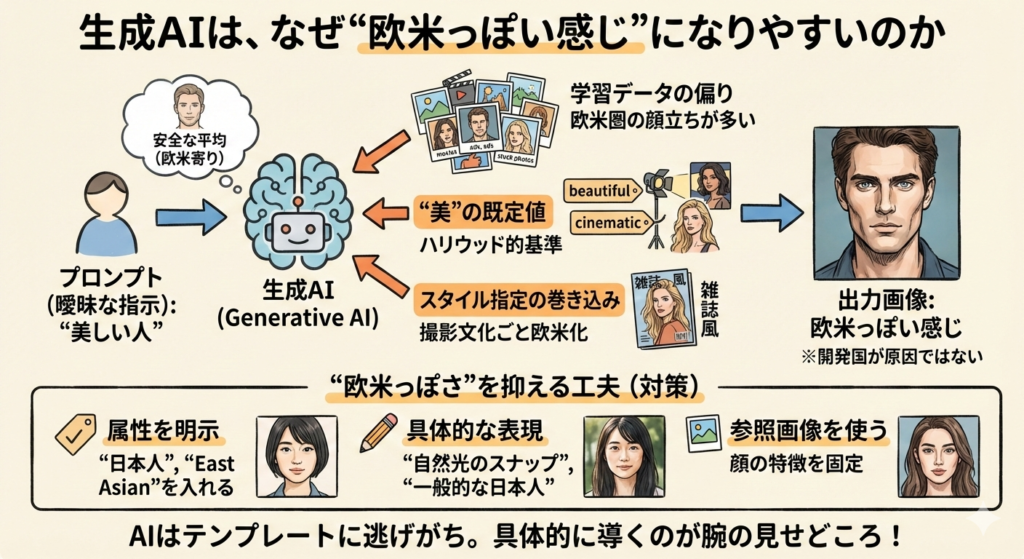
AIは便利ですが、放っておくとテンプレートに逃げがちです。少し具体的に指示するだけで、驚くほど素直に働き出します。そこをうまく導くのが、使い手の腕の見せどころです。


