
「お勉強ができるAI → 仕事ができるAI」になった感もある。
正直、Gemini 3 により「GoogleがAI覇権に再浮上した」印象
| ベンチマーク名 | テスト内容(日本語) | Gemini 3 Pro | Gemini 2.5 Pro | Claude Sonnet 4.5 | GPT-5.1 |
|---|---|---|---|---|---|
| Humanity’s Last Exam | 学術的推論 | 37.5% /(検索+コード実行: 45.8%) | 21.6% | 13.7% | 26.5% |
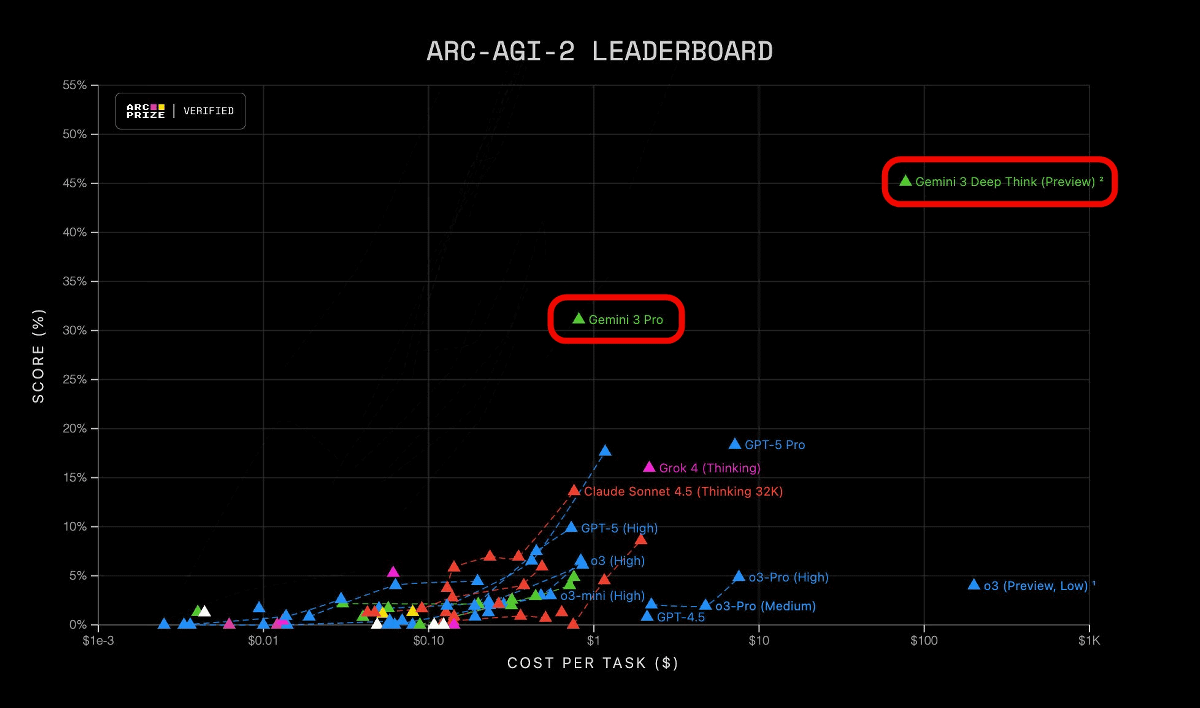
| ARC-AGI-2 | 高度な視覚パズル推論 | 31.1% | 4.9% | 13.6% | 17.6% |
| GPQA Diamond | 最難関の科学知識テスト | 91.9% | 86.4% | 83.4% | 88.1% |
| AIME 2025 | 数学(AIME) | 95.0%(コード実行: 100%) | 88.0% | 87.0%(コード実行 100%) | 94.0% |
| MathArena Apex | 上級数学コンテスト問題 | 23.4% | 0.5% | 1.6% | 1.0% |
| MMMU-Pro | マルチモーダル推論 | 81.0% | 68.0% | 68.0% | 76.0% |
| ScreenSpot-Pro | 画面理解(UI 解析) | 72.7% | 11.4% | 36.2% | 3.5% |
| CharXiv Reasoning | 複雑な図表からの情報推論 | 81.4% | 69.6% | 68.5% | 69.5% |
| OmniDocBench 1.5 | OCR(文書の読み取り)※低いほど良い | 0.115 | 0.145 | 0.145 | 0.147 |
| Video-MMMU | 動画からの知識抽出 | 87.6% | 83.6% | 77.8% | 80.4% |
・科学知識(GPQA Diamond)で首位
・画面理解(ScreenSpot-Pro)は他のモデルを圧倒。AIAgentに有利
・数学(AIME)もコード実行で満点を取る
・視覚パズル(ARC-AGI-2)で 2.5 Pro から大幅改善

