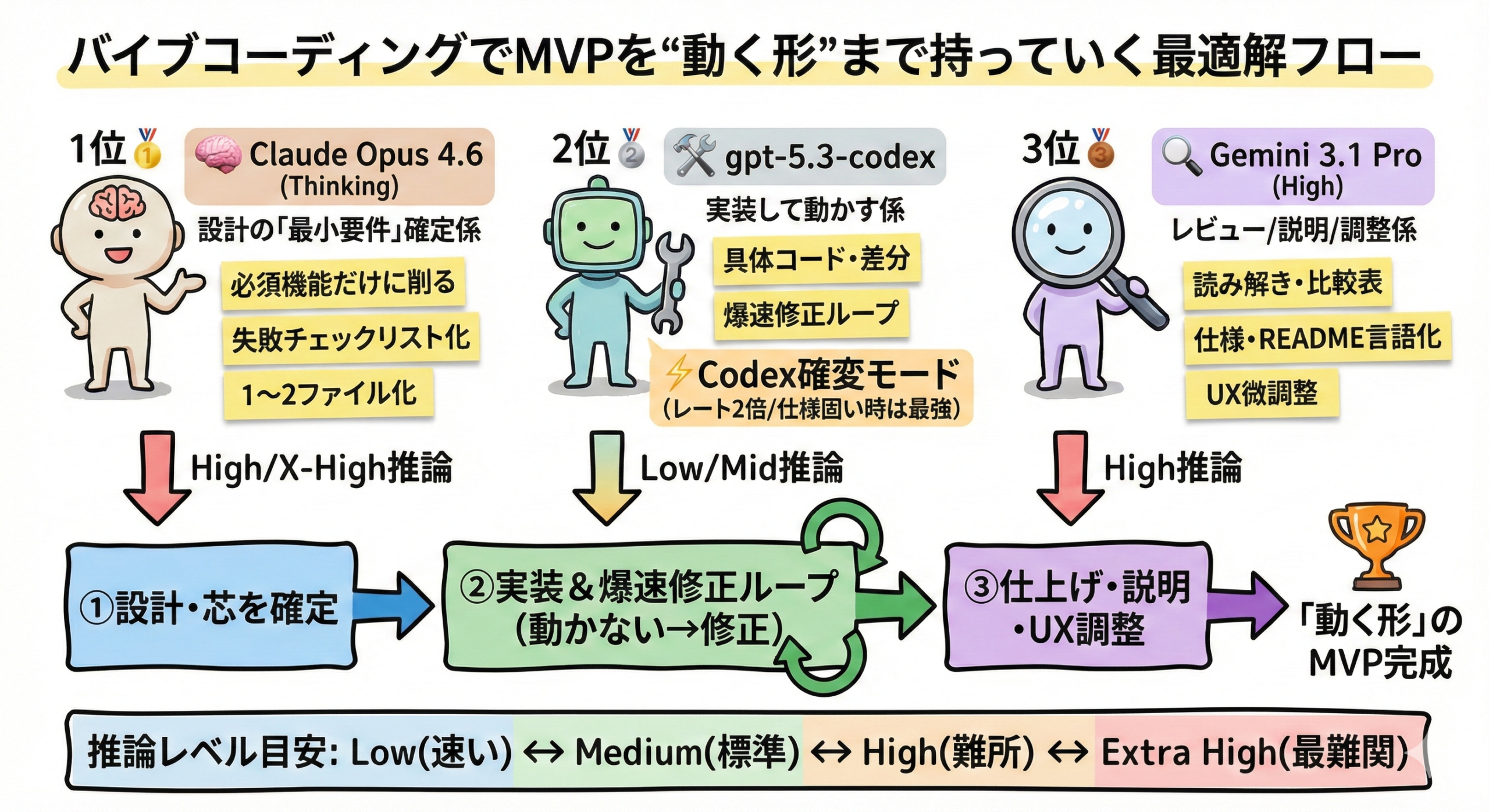
「バイブコーディングでMVPを“動く形”まで持っていく」という用途だと、
- 1位:Claude Opus 4.6 (Thinking):設計の整合性・抜け漏れ潰し・長期記憶(会話内の一貫性)が強い
- 2位:gpt-5.3-codex:実装速度・差分生成・修正ループ(バグ→パッチ)が強い
- 3位:Gemini 3.1 Pro (High):広い文脈処理や説明は強いが、MVP実装の「手触り」は上2つに一歩譲ることがある
…という順位になると思います。

使い分けるなら今のところ以下のような感じでしょうか。
1) Opus:設計の「最小要件」を確定する係
- MVPで必須の機能/画面/データだけに削る
- 失敗しやすい点(依存・状態・認証・例外)を短いチェックリスト化
- 実装方針を「1ファイル/2ファイルで済む形」に落とす
2) codex:実装して動かす係
- 具体コード、差分、修正ループはcodexが強い
- 「動かない→原因→最小修正」の反復が速い
3) Gemini:レビュー/説明/文章/UX微調整係
- 既存コードの読み解き補助、比較表作り
- README、操作手順、UI文言、仕様の言語化
codexを上位にする場面

ChatGPTユーザーは、OpenAIの案内では、一定期間 Plus/Pro等でCodexのレート上限が2倍。状況によってはcodexが一番。
- 仕様が固い / 既存コードにパッチ当て続ける
- テスト追加・型修正・lint対応など手数の勝負
- “設計の良さ”より“修正の速さ”が成果に直結

Low:速い/軽い(MVPの叩き台・単純修正向き)
Medium:標準(普段はここで十分)
High:難所向き(設計の整合性、複雑バグ、依存関係が絡む時)
Extra high:だいたい xhigh 相当(最難関だけ。遅くなりやすい