

コーディング力だけに絞り、しかも「バイブコーディング向きか」という観点で並べます。
根拠は各社の公式な位置づけです。ただし点数は、公式のベンチマークではなく、公式の説明を土台にした実務感ベースの相対評価だと捉えてください。
比較の柱は4つです。初速、雑な指示への強さ、修正の追従、そして壊しにくさ。バイブコーディングで効くのは結局ここなので、他は切ります。
この4軸を実際の作業に落とすと、見る項目は次の6つになります。初版を雑に出す力、継ぎ足し改修のうまさ、既存コード読解、バグ修正、大きめ変更で崩れにくいか、最終品質です。
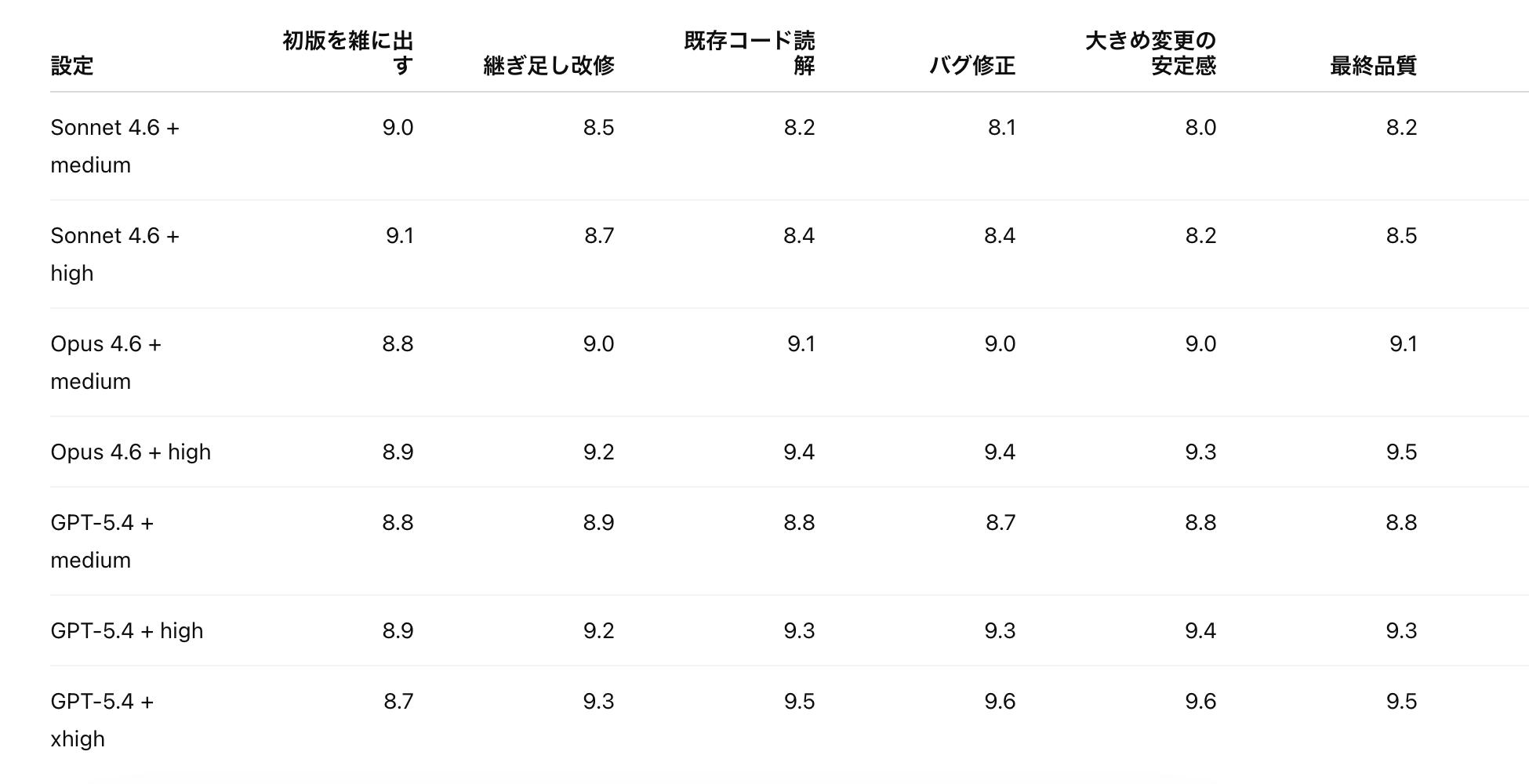
前提を揃えると、OpenAI は GPT-5.4 を「agentic / coding / professional workflows 向けの主力」と案内し、none / low / medium / high / xhigh の reasoning.effort を持っています。
さらに GPT-5.4 は “fewer iterations” を強みとして案内されています。
Anthropic は Sonnet 4.6 を「everyday coding 向けのバランス型」、Opus 4.6 を「complex coding / deep reasoning 向けの最上位」と位置づけ、Claude Code では /effort low / medium / high が使えます。


